尽管phi-1的训练规模较小,但其表现明显优于其他模型 原图定位 高质量数据是全球人工智能竞争的“胜负手”:数据质量及其包含的有用信息量是决定机器学习算法学习能力的关键因素。因此在将数据集提供给机器学习算法之前,确保对数据集进行检查和预处理至关重要。高质量的数据可提高大型语言模型(LLM)的 SOTA(例 phi-1),同时可大幅减少数据集大小和训练计算,并可显著降低 LLM 的训练成本。
 报告分类
报告分类
 新质生产力
新质生产力
 ChatGPT
ChatGPT
 新能源汽车
新能源汽车
 大模型
大模型
 Sora
Sora
 机器人
机器人
 微短剧
微短剧
 芯片
芯片
 薪酬
薪酬
 白皮书
白皮书
 低空经济
低空经济
 数据要素
数据要素
 创新药
创新药
 人工智能
人工智能
 AI产业
AI产业
 信息科技
信息科技
 互联网
互联网
 消费经济
消费经济
 汽车交通
汽车交通
 电商零售
电商零售
 传媒娱乐
传媒娱乐
 医药健康
医药健康
 投资金融
投资金融
 能源环境
能源环境
 地产开发
地产开发
 传统产业
传统产业
 全球化
全球化
 其它
其它














")
")





 sgpjbg002
sgpjbg002 工作日 8:30 - 17:30
工作日 8:30 - 17:30 收藏
收藏
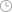 2024-04-07
2024-04-07 19人已浏览
19人已浏览 打包下载
打包下载












 扫码登录
扫码登录




 手机快捷登录
手机快捷登录

 账号登录
账号登录

