2023年H100GPU出货客户估算 原图定位 Scaling-law 助推参数量、数据量高速扩张,训练需求仍在攀升。1)Scaling-law 简单理解即为,随着模型大小、数据集大小和用于训练的计算浮点数的增加,模型的性能会提高;并且为了获得最佳性能,所有三个因素必须同时放大。根据华尔街见闻报道,GPT4在 120 层中总共包含了或约 1.8 万亿参数量,而 GPT3 只有约为 1750 亿个参数,规模提升约 10 倍;同时,GPT4 的训练数据集包含 13 万亿个 token,彼时单次训练成本约为6300 万美元。2)为了在大模型上取得竞争优势,以微软、谷歌、Meta 等为代表的科技大厂,在 AI 智算建设上的投入仍在快速扩大,力度空前。根据新智元报道,微软与 OpenAI正计划建设“星际之门”项目,将配备数百万专用的超算服务器芯片,项目成本预计超千亿美元;Meta 计划于 2024 年底拥有 35 万张英伟达 H100GPU,未来算力储备将达到60 万张。
 报告分类
报告分类
 新质生产力
新质生产力
 ChatGPT
ChatGPT
 新能源汽车
新能源汽车
 大模型
大模型
 Sora
Sora
 机器人
机器人
 微短剧
微短剧
 芯片
芯片
 薪酬
薪酬
 白皮书
白皮书
 低空经济
低空经济
 数据要素
数据要素
 创新药
创新药
 人工智能
人工智能
 AI产业
AI产业
 信息科技
信息科技
 互联网
互联网
 消费经济
消费经济
 汽车交通
汽车交通
 电商零售
电商零售
 传媒娱乐
传媒娱乐
 医药健康
医药健康
 投资金融
投资金融
 能源环境
能源环境
 地产开发
地产开发
 传统产业
传统产业
 全球化
全球化
 其它
其它












")
")





")

 sgpjbg002
sgpjbg002 工作日 8:30 - 17:30
工作日 8:30 - 17:30 收藏
收藏
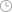 2023-12-04
2023-12-04 70人已浏览
70人已浏览 打包下载
打包下载












 扫码登录
扫码登录




 手机快捷登录
手机快捷登录

 账号登录
账号登录

