GPT-3的In-context方式与传统微调方式的对比 原图定位 2020 年 5 月, GPT-3 正式发布,GPT-3 在训练方式上创新性的引入了 In-context 学习(上下文学习),即在训练模型时,在输入的文本中加入一个或多个示例,引导模型输出相对应内容。比如:“请把以下中文翻译成英文:苹果 => apple;自然语言处理的发展历程”就是一个典型的带有一个示例的输入文本。而 In-context 学习包含了三种模式,分别为 Zero-shot Learning(零样本学习)、One-shot Learning(单样本学习)和 Few-shot Learning(少样本学习),zero-shot 就是没有示例只给提示,one-shot 是只给一个范例,few-shot 则给多个范例,实际上 zero-shot 在表达方式上已经接近于人类的语言表达方式。In-context 学习的优点在于,输入规范化的语言模板,从人类的例子和类比中去学习,无需进行模型微调和数据标注,特别是大量的标注数据需要很高的人工成本。引入 In-context 学习后,从最终实际效果来看,GPT-3 在 few-shot 上有非常强劲的表现,但同时 one-shot 和zero-shot 的效果还不够优秀。因此对于 one-shot 和 zero-shot 效果的提升也成为了下一代模型未来需要突破方向。
 报告分类
报告分类
 新质生产力
新质生产力
 ChatGPT
ChatGPT
 新能源汽车
新能源汽车
 大模型
大模型
 Sora
Sora
 机器人
机器人
 微短剧
微短剧
 芯片
芯片
 薪酬
薪酬
 白皮书
白皮书
 低空经济
低空经济
 数据要素
数据要素
 创新药
创新药
 人工智能
人工智能
 AI产业
AI产业
 信息科技
信息科技
 互联网
互联网
 消费经济
消费经济
 汽车交通
汽车交通
 电商零售
电商零售
 传媒娱乐
传媒娱乐
 医药健康
医药健康
 投资金融
投资金融
 能源环境
能源环境
 地产建筑
地产建筑
 传统产业
传统产业
 英文报告
英文报告
 其它
其它






")






架构")
")


")
")


 sgpjbg002
sgpjbg002 工作日 8:30 - 17:30
工作日 8:30 - 17:30 收藏
收藏
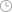 2024-07-02
2024-07-02 9人已浏览
9人已浏览 打包下载
打包下载












 扫码登录
扫码登录




 手机快捷登录
手机快捷登录

 账号登录
账号登录

