国内主流大模型或产品访问量情况 原图定位 特点#3:上下文作为 LLM 的内存,是实现模型通用化的关键 国外 LLM 厂商较早实现长上下文,国内厂商通过长上下文找到差异化竞争优势。国外较早实现长上下文的厂商是 Anthropic,旗下 Claude模型在 23年 11月,将支持的上下文从 100K tokens 提升到 200K,同时期的 GPT-4 维持在 128K。24 年 2 月,Google 更新 Gemini 到1.5 Pro 版本,将上下文长度扩展到 1M(5 月更新中扩展到 2M),并在内部实现了 10M, 是目前已 知最大上下文长度。国内方面,23 年 10 月由 月之暗面发布的 Kimi 智能助手(原名 Kimi Chat),率先提供 20 万字的长上下文,并在 24 年迎来了用户访问量的大幅提升。24 年 3 月,阿里通义千问和 Kimi 先后宣布支持 1000 万字和 200 万字上下文,引发国内百度文心一言、360 智脑等厂商纷纷跟进长上下文能力迭代。我们认为,国内 LLM 厂商以长上下文为契机,寻找到了细分领域差异化的竞争路线,或有助于指导后续的模型迭代。
 报告分类
报告分类
 新质生产力
新质生产力
 ChatGPT
ChatGPT
 新能源汽车
新能源汽车
 大模型
大模型
 Sora
Sora
 机器人
机器人
 微短剧
微短剧
 芯片
芯片
 薪酬
薪酬
 白皮书
白皮书
 低空经济
低空经济
 数据要素
数据要素
 创新药
创新药
 人工智能
人工智能
 AI产业
AI产业
 信息科技
信息科技
 互联网
互联网
 消费经济
消费经济
 汽车交通
汽车交通
 电商零售
电商零售
 传媒娱乐
传媒娱乐
 医药健康
医药健康
 投资金融
投资金融
 能源环境
能源环境
 地产建筑
地产建筑
 传统产业
传统产业
 英文报告
英文报告
 其它
其它





")
")





")


")
")
")
")


 sgpjbg002
sgpjbg002 工作日 9:30 - 18:00
工作日 9:30 - 18:00 收藏
收藏
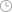 2024-07-03
2024-07-03 13人已浏览
13人已浏览 打包下载
打包下载




")







 扫码登录
扫码登录




 手机快捷登录
手机快捷登录

 账号登录
账号登录

