 报告分类
报告分类


图1从基于规则到遵循人的价值观,大型语言模型变迁由来已久
原图定位
1.1. NLP 五级进阶,大模型应运而生 ............................................ 3 1.2. 从 CNN 到 Transformer,大模型底层架构显著优化 ................. 3 1.3. 大模型技术路线各有侧重,MaaS 已成产业趋势 ..................... 5 2. GPT 系列一路领先,海外大模型角逐激烈 .................................... 6 2.1. OpenAI:GPT 系列大模型一骑绝尘,智能化程度提升迅速 ....... 6 2.2. 微软:与 OpenAI 深度绑定,占得行业先机 .......................... 10 2.3. 谷歌:扎根基础模型研发,引领技术革新 ............................ 13 3. 国内大模型蓄力已久,赶超动能强劲 ......................................... 16 3.1. 百度:全栈技术积累颇丰,AI 应用场景全覆盖 .................... 16 3.2. 腾讯:优化大模型训练,加速大模型应用落地 ..................... 20 3.3. 阿里:聚焦通用底层技术,开源释放大模型应用潜力 ........... 21 3.4. 华为:昇腾 AI 打造全栈使能体系,定位行业级 CV 应用 ...... 23 4. 算力及硬件承压,模型训练多路径优化 ...................................... 25 4.1. 海量参数开路,算力瓶颈渐至 .............................................. 25 4.2. 模型日益复杂,硬件需求承压 .............................................. 27 4.3. 聚焦技术路线优化,突破模型算力瓶颈 ................................ 28 5. 投资建议 ................................................................................... 31 6. 风险提示 ................................................................................... 31 1. 大模型构筑 AI 基石,MaaS 未来可期 1.1. NLP 五级进阶,大模型应运而生 从基于规则到基于人的意识,大型语言模型是技术进步的必然产物。自然语言处理发展到大型语言模型的历程可分为五个阶段:规则、统计机器学习、深度学习、预训练、大型语言模型。考虑到机器翻译是 NLP 中难度最高、综合性最强的任务,可借助该功能来论述不同技术阶段的典型特点。从 1956 年到 1992 年,基于规则的机器翻译系统在内部把各种功能的模块串到一起,由人先从数据中获取知识,归纳出规则后教给机器,然后由机器执行这套规则,该阶段为规则阶段;从 1993 年到 2012年是统计机器学习阶段,在此期间,机器翻译系统可拆成语言模型和翻译模型,该阶段相比上一阶段突变性较高,由人转述知识变成机器自动从数据中学习知识,当时人工标注数据量在百万级左右;从 2013 到 2018年,进入深度学习阶段,其相比于上一阶段突变性较低,从离散匹配发展到 embedding 连续匹配,模型变得更大,标注数据量提升到千万级;预训练阶段存在于 2018 年到 2022 年,跟之前比较,最大变化是加入了NLP 领域杰出的自监督学习,将可利用数据从标注数据拓展到了非标注数据。该阶段系统可分为预训练和微调两个阶段,将预训练数据量扩大3 到 5 倍,典型技术栈包括 Encoder-Decoder、Transformer、Attention等。

 收藏
收藏
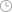 2023-12-26
2023-12-26 0人已浏览
0人已浏览
的日本世俗价值观")




















 sgpjbg002
sgpjbg002 工作日 8:30 - 17:30
工作日 8:30 - 17:30





